Blog
LLMs in Production 103: Make Sure Your LLM Isn’t Telling “Lies”

Introduction
Google's AI Search feature, AI Overviews, encountered significant issues due to generating flawed and potentially harmful results. Introduced by CEO Sundar Pichai, the feature aimed to provide comprehensive summaries above traditional search results, sourced from some of the “most reliable and most referred to sources on the internet”, Reddit being one of them. However, it produced several notable errors, such as recommending glue for pizza recipes and suggesting the ingestion of rocks for nutrients.
These inaccuracies led to the feature being scaled back, with a focus now on generating simple factual summaries and often defaulting to only known and verified sources for more complex queries. Widespread mockery and scrutiny, particularly regarding misleading health-related advice, prompted Liz Reid, Google's new head of search, to emphasize ongoing refinements to avoid such errors and exclude satire and forum responses. Despite these setbacks, Google continues to update the feature to improve its accuracy, safety and factual correctness.
This whole fiasco highlighted a very serious issue with LLMs– the reliability and factual correctness of the responses they generate.
What is Factual Correctness?
LLMs generate natural language responses based on a probabilistic modeling approach. While these responses may appear grammatically and lexically correct, they can sometimes deviate from actual facts– a phenomenon known as “LLM hallucination.” Frequent hallucinations reduce the reliability of the LLM.
Factual correctness refers to how well an LLM’s response aligns with verified facts. It is critical for maintaining trust, safety, and stability in AI systems.
For instance, in healthcare, inaccuracies can lead to misdiagnosis and incorrect treatments, endangering lives and increasing costs. In finance, errors can result in poor investment decisions and regulatory breaches, causing financial instability and reputational damage.
Therefore, robust testing and stringent quality control are necessary to ensure the reliability of LLM outputs. Ensuring factual correctness involves rigorous verification processes and sourcing from credible references to avoid misinformation.

Strategies To Improve LLM’s Factual Correctness And Accuracy In Production
Improving the factual correctness and accuracy of a large language model (LLM) in a production environment involves several strategies, ranging from data preprocessing to model architecture enhancements. Here are some popular techniques:
Data-Centric Technique

Data-centric techniques prioritize the quality, relevance, and integrity of data used in training and fine-tuning LLMs.
High-Quality Training Data: Ensuring high-quality training data involves removing noise, errors, and irrelevant information. Data cleaning techniques help ensure that the LLM learns from accurate and reliable data, leading to more accurate model outputs. Focusing on domain-specific data from authoritative sources ensures the model learns to generate responses that are relevant and contextually appropriate for the target application or industry.
Data Augmentation: Data augmentation generates additional training data by transforming or perturbing existing data, increasing its diversity and coverage. Techniques like paraphrasing and word substitution help the model understand various linguistic patterns and contexts. This improves performance, reduces overfitting, and enhances adaptability to domain-specific tasks, making the model more robust and effective across different natural language processing tasks.
Bias Detection and Mitigation: Identifying and addressing biases in training data is essential for fairness and accuracy. Bias detection algorithms and debiasing methods help ensure the model generates impartial and unbiased outputs, improving the overall reliability and trustworthiness of the LLM.
Model-Centric Techniques
Model-Centric Techniques focus on improving the architecture, training process, and performance of LLMs to enhance their accuracy, efficiency, and robustness. These techniques aim to optimize the model itself rather than the data used for training.
Fine-tuning using domain-specific data is a common methodology. This process involves further training an LLM using datasets specific to a particular field, enhancing its understanding and performance in that domain. For example, to improve proficiency in medical terminology, the LLM can be fine-tuned with medical journals, textbooks, and healthcare databases.
Some effective fine-tuning strategies include:
Low-Rank Adaptation (LoRA)

Objective: LoRA is a parameter-efficient fine-tuning (PEFT) technique that reduces the number of trainable parameters in LLMs while maintaining performance. It achieves this by introducing smaller rank decomposition matrices, which capture essential task-specific information while freezing the original model weights.
Example: Assume you want to train a Llama3-70B model to process legal documents. Doing a full supervised fine-tuning (SFT) would require several weeks of training on expensive compute resources, amounting to a huge operational cost. A LoRA-based fine-tuning would require only the adapter matrices to be trained, resulting in a shorter training duration and hence a much smaller investment.
Reinforcement Learning with Human Feedback (RLHF)

Objective: RLHF integrates human evaluations into the training process of LLMs to enhance their performance. Human feedback serves as a crucial signal for the model, guiding it towards producing more accurate, relevant, and human-aligned responses.
Example: Suppose you are developing a chatbot for customer support. During training, human evaluators assess the responses generated by the chatbot based on criteria such as accuracy, relevance, and tone. The chatbot then uses reinforcement learning techniques to adjust its decision-making process and improve its responses based on the feedback received from humans. Over time, the chatbot learns to generate more accurate and helpful responses, enhancing its performance in customer interactions.
Reinforcement Learning from AI Feedback (RLAIF)

Objective: RLAIF is similar to the RLHF method, except for the fact that the evaluator in the feedback loop is another AI model. This serves to be a more cost-efficient and scalable technique as compared to RLHF.
Adversarial Training

Objective: Adversarial training involves training the model using adversarial examples to make it more robust against incorrect or misleading information. Techniques like Direct Preference Optimization (DPO) involves training a model by optimizing its outputs based on direct comparisons between preferred and less preferred outputs, enhancing the model’s ability to produce accurate and desirable results.
Example: Expose the model to intentionally misleading medical case studies to improve its ability to identify and correct inaccuracies.
Knowledge Integration Techniques
Knowledge integration involves incorporating context/information from external knowledge bases directly into the generation pipeline of a language model. This integration enables the model to access structured/unstructured factual information in real-time during the inference process, enhancing its understanding and generating more informed responses. It includes :
External Knowledge Bases: Relational databases, data repositories like Wikidata and ConceptNet, documentation and records contain vast amount of structured information, including facts, relationships, and concepts, curated from various sources.
Integration into the Model: In the context of a language model, integration involves embedding these knowledge bases into the inference pipeline, allowing the model to retrieve and utilize their contents seamlessly during inference.
Accessing Retrieved Information: During inference, the model can query the integrated knowledge bases to retrieve relevant facts, relationships, or concepts related to the input text or task at hand.
The following strategies incorporate knowledge integration:
Retrieval-Augmented Generation (RAG)
RAG combines generative capabilities of LLMs with retrieval-based methods to improve the factual accuracy and relevance of model outputs. It incorporates a retrieval mechanism to retrieve relevant passages of text from a knowledge base, which are then used to generate more accurate and contextually relevant responses. We have another blog discussing RAG in detail that you can follow here.

Retrieval Augmented Fine-Tuning (RAFT)
RAFT enhances the training of language models by integrating relevant external knowledge from a retrieval system into the fine-tuning process. The technique involves periodic fine-tuning of the foundational model on the most relevant external documents or data retrieved in response to specific queries or contexts, hence reducing domain shift too in addition to hallucination.

Consider an LLM deployed for customer support queries in a software company. With RAG, the model not only generates responses but also retrieves relevant information from the company's knowledge base, such as FAQs or documentation. This retrieval mechanism ensures that the responses are both accurate and contextually relevant to the user's query. In contrast, RAFT fine-tunes the LLM specifically for this domain, training it to utilize the company's specific documents for reference during generation. This focused fine-tuning process enhances the LLM's ability to provide precise and helpful responses tailored to the software domain, akin to having access to a specialized library of information during the support interaction.
Fact-Checking Mechanisms
Incorporating real-time fact-checking mechanisms into large language models involves creating a system that continuously evaluates the model's outputs against reliable sources or pre-existing knowledge bases. This process enhances the accuracy and credibility of the information generated by the LLM.
External Knowledge References

Incorporation: At its core, this mechanism would involve integrating APIs or modules that access reputable databases, such as academic journals, encyclopedias, news outlets, search engine results, etc. As the LLM generates responses, these mechanisms would swiftly cross-reference the information provided with the data in these sources.
Example: PerplexityAI is an AI chatbot-powered research and conversational search engine that answers queries using natural language predictive text. Perplexity generates answers using sources from the web and cites links within the text response.
Human-in-the-Loop
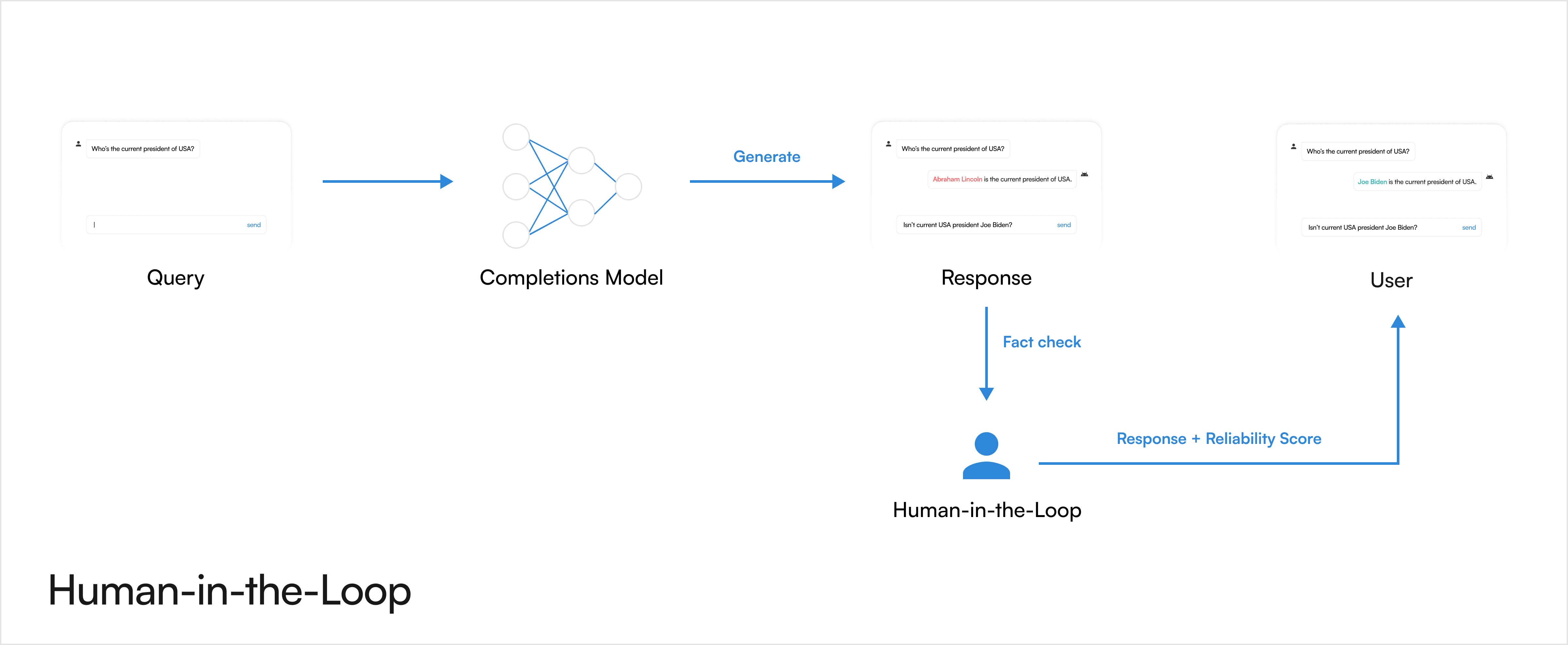
Incorporation: This technique integrates human oversight into the model’s output pipeline, where domain experts or trained reviewers evaluate and rate/correct the LLM’s responses before they reach the end-user. The errors or ambiguities that the model might miss can be identified using this process. Experts can additionally ensure the responses are contextually appropriate and adhere to required standards. Although, this is an expensive and resource intensive process, and can additionally be affected by evaluator’s bias.
Example: Let's say a company uses an LLM-powered chatbot to provide customer support. To ensure accuracy and quality control, they employ human reviewers to evaluate the responses generated by the chatbot before they are sent to customers.
The collected feedback can also be incorporated into the model’s training and fine-tuning processes to adjust model parameters and retrain the model periodically. Additionally, the ability for users to flag outdated information can also be added to the feedback loop. System notes and analyzes the feedback. Model parameters are adjusted in the next training cycle for more accurate responses. This iterative process enhances user experience.
Conclusion
Ensuring factual correctness and accuracy in LLMs is vital for maintaining trust, safety, and stability, especially in high-stakes environments like healthcare and finance. Implementing robust data-centric, model-centric, and post-processing techniques, along with continuous monitoring and user feedback integration, helps achieve reliable and trustworthy AI systems. These strategies are essential to uphold quality control, prevent misinformation, and foster user confidence in AI technologies.